AI and Machine Learning (ML) models have unlocked a new engine for companies to harness the vast swathes of data available to them to improve their performance and profitability. Fields such as healthcare, finance, and logistics are reaping big harvests from the implementation of big data models.
Amidst the availability of all this data, both from public and private hands, privacy remains a top concern. Any model AI/ML model that uses public or private data for its implementation needs to be empowered for data protection, to protect against leakages
In this article, we’ll quickly go through how privacy is protected in AI/ML models and how you can keep confidential data discrete in your own model. We’ll also explore the importance of Privacy-Preserving Machine Learning (PPML) and how it has become crucial in cloud-based environments and collaborative work settings.
Why Privacy Matters in Machine Learning
Let’s assume you are a researcher building an ML model for a major healthcare group. The possibilities of your research could range from medical diagnostics to cancer research. In this case, your model would be able to access enterprise data from the servers of the healthcare group. Some of this data would be confidential and would either need to be encrypted, or randomized in a way. If your data model doesn’t fulfill the requirements of data protection statutes and laws, you may be limited in your research.
This is the same problem that many ML models face. According to a study by Protopia AI, 75% of enterprise data goes unused due to AI models not being able to fulfill data privacy concerns. Many other applications, such as search algorithms, recommender systems, and advertising networks, rely on machine learning, making them privacy-sensitive. To maintain the privacy of sensitive data and adhere to data protection regulations, the field of privacy-preserving machine learning has emerged.
Since this is quite a technical subject you can pay for essay professionals to provide sample scholarly papers that further elaborate on the theoretical perspectives of the subject.
What is PPML?
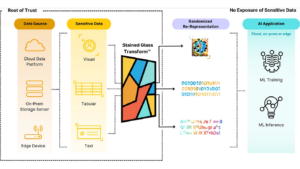
Privacy-Preserving Machine Learning (PPML) is a comprehensive approach aimed at preventing data leakage in machine learning algorithms. It enables multiple parties to collaboratively train ML models without revealing their sensitive data in its original form.
With the growing prevalence of cyberattacks and data breaches, there’s a significant risk not only to data security but also to the very ML models themselves. PPML approaches may include using techniques such as Synthetic Data, anonymized or de-identified data, or even encryption, all of which may damage the quality of ML models. One such technique is the Randomized Re-Representation of data through an AI model like Protopia, in the image above.
The top concern is to protect and safeguard Personally Identifiable Information (PII) to enable compliance with data protection regulations like GDPR.
Privacy-Preserving Strategies for Machine Learning
To address the challenges posed by data privacy in the realm of machine learning, privacy-preserving machine learning (PPML) employs various strategies and techniques. These strategies aim to protect data privacy, secure the training process, and ensure the integrity of ML models.
The four main stakes of privacy-preserving machine learning include:
- Data Privacy in Training: This ensures that malicious parties cannot reverse-engineer the training data.
- Privacy in Input: It prevents access to a user’s input data by other parties.
- Privacy in Output: Ensures that the output of an ML model is only accessible to the client whose data is being inferred.
- Model Privacy: Protects machine learning models from theft or reverse engineering.
At any of these stages of data training, the ML model needs to be safeguarded for privacy.
Techniques in PPML
Various techniques are used in Privacy Preserving Machine Learning models. These include:
Differential Privacy: This technique involves adding random noise to data to prevent the disclosure of personal information. However, it may impact data reliability.
Homomorphic Encryption: It allows computations on encrypted data without revealing the original input, preserving data quality.
Federated Learning: By decentralizing ML processes, it reduces data exposure and identity risks.
Multi-party Computation: This enables parties to compute functions without disclosing their private inputs, enhancing data privacy.
All of these techniques can be combined in an ensemble model to enhance privacy and reduce vulnerabilities.
PPML Tools
Various tools and libraries are available to implement PPML techniques:
- PySyft: An open-source Python-based ML toolbox supporting differential privacy, homomorphic encryption, multi-party computation, and federated learning.
- TensorFlow Privacy (TFP): A Python toolbox for training differentially private ML models.
- CrypTFlow: Combines programming languages and multi-party computation to securely query ML models.
- ML Privacy Meter: Assesses privacy threats in ML models and generates privacy reports.
- CrypTen: A privacy-preserving ML framework based on PyTorch.
Regardless of the technique being used, data must be secured across the entire ML lifecycle, ranging from data collection and preparation, data analysis, the machine learning phase, and the model productization phases.
Data Science Expertise and Privacy in ML Models
PPML and other mechanisms of protecting sensitive data in ML models are abridged with the field of data science. While often viewed as a concern for cryptographers, data scientists need to understand how privacy strategies can affect data and model results.
With the pervasiveness of cloud-based technologies and machine learning models hosted on such cloud architecture, data scientists need to come up with ingenious ways of striking a balance between application-specific concerns and platform-independent methodologies.
An education in data science puts you in the best position to follow a career in AI and Machine Learning, to develop or integrate technologies such as PPML. With the rise in cyberattacks, data breaches, and the risk of sensitive data exposure, data scientists are a hot commodity across a wide array of industries.
Wrapping Up
Privacy in AI and ML models has never been more crucial than in 2023. Huge amounts of data harnessed from the internet or enterprise sources are now available to ML engineers. However, such models need to be safeguarded against data leakages, loss, or intrusion, thus ensuring compliance with data protection laws.
By leveraging PPML techniques and tools such as Protopia AI, organizations can harness the power of machine learning while preserving data privacy and minimizing risks.